
Comparatif des modes de machine learning : une matrice pour choisir

Dans son dernier livre blanc sur l'intelligence artificielle, l'ESN française experte en data et IA Business & Decision, filiale d'Orange, a dressé un comparatif des techniques de machine learning. Publié en exclusivité par le JDN (voir ci-dessous), il permet en un coup d'œil de cerner les principaux points forts et contraintes de chaque type d'entrainement. "Il s'agit d'un tableau de synthèse des grandes tendances qui se détachent par mode d'apprentissage. Parmi nos indicateurs, on pourra évidemment trouver des exceptions", prévient Didier Gaultier, directeur data science & AI chez Business & Decision. "Il s'adresse en premier lieu aux chief data officer, chief AI officer, et autres responsables en data et IA en quête d'une matrice de choix sur le front du machine learning."
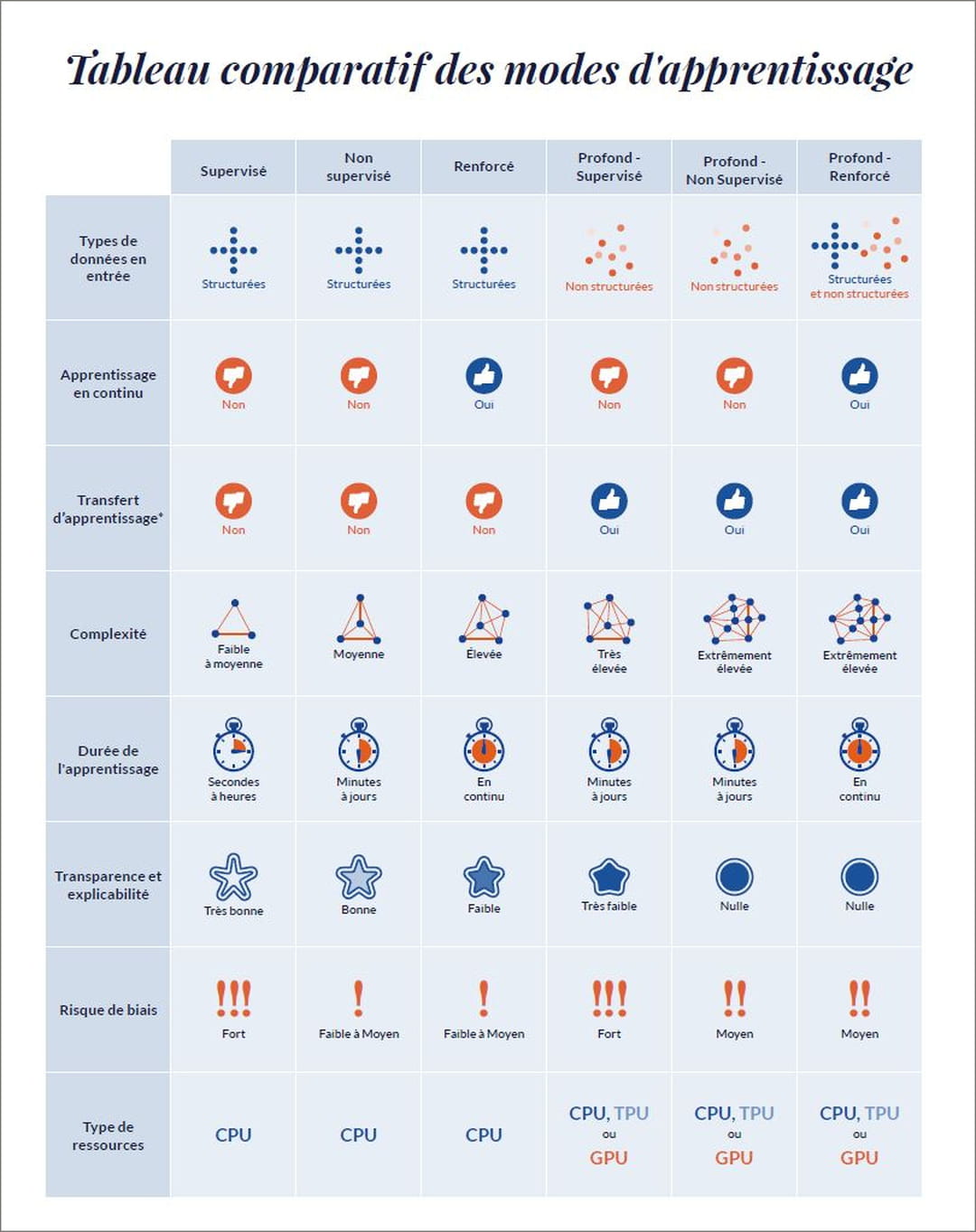
"Que ce soit pour le machine learning simple ou le deep learning, l'apprentissage supervisé reste le mode d'entraînement le plus utilisé", rappelle Didier Gaultier. Principale contrainte : bénéficier d'un volume de données labellisées suffisamment important pour former le modèle. "Nous avons travaillé pour une Mutuelle qui souhaitait développer un moteur de détection de fraudes. Elle ne disposait pas d'une base d'exemples de fraudes qualifiés. Du coup, nous avons dû nous rabattre dans un premier temps sur une approche non-supervisée. Ce qui nous a permis de dégager une typologie comptant quelque 1 000 dossiers susceptibles de contenir des fraudes parmi des dizaines de millions. Une équipe les a ensuite épluchés et y a découvert une centaine de fraudes avérées. Partant de là, nous avons pu créer un data set labellisé sur lequel lancer l'apprentissage supervisé."
La question toujours épineuse des biais
Le machine learning comme le deep learning supervisé présentent un risque particulièrement élevé d'aboutir à des biais dans les prédictions du modèle. Des biais qui peuvent avoir deux origines. La première : les données d'apprentissage. Un exemple ? Une étude publiée en 2018 par le MIT Media Lab a démontré que les applications de reconnaissance faciale de l'époque affichaient un taux de réussite plus élevé pour les hommes à la peau blanche, et ce du fait d'images d'entraînement sur lesquelles ces derniers étaient surreprésentés. "D'où l'importance, en particulier dans le cas de l'apprentissage supervisé, de porter une attention toute particulière au contenu des données utilisées", insiste Didier Gaultier. Seconde source de biais : les caractéristiques intrinsèques du modèle. Pour éviter de voir le feature engineering biaiser les résultats, une analyse factorielle permettra de mettre le doigt sur les variables manquantes ou les dimensions redondantes.
"On pourra aussi faire une analyse statistique en injectant en entrée du modèle une classe normée, puis en vérifiant que le résultat correspond", poursuit Didier Gaultier. De quoi analyser l'homogénéité de la variance des réponses, et d'anticiper, avant qu'elles ne surviennent, les potentielles déviances, incohérences ou erreurs.
Les erreurs du reinforcement learning
Qu'il soit profond ou pas, l'apprentissage renforcé se caractérise quant à lui par une formation en continue. A la différence de l'apprentissage supervisé ou non-supervisé qui figent le modèle jusqu'à une prochaine phase d'entraînement. Sans surprise, le reinforcement learning est très utilisé pour les moteurs de churn et de recommandation de produits. Des bots qui nécessitent des feedbacks clients permanents pour prendre en compte l'évolution de l'offre et des appétences. Revers de la médaille : l'apprentissage par renforcement apprend de ses erreurs. Il est par conséquent nécessaire d'accepter qu'il se trompe. "Il est possible de jouer, à la marge, sur le taux d'erreur pour éviter un trop grand nombre de faux positifs. Pour un modèle de churn, cette méthode permettra d'ajuster le ROI en évitant qu'un commercial se déplace chez un client qui serait identifié à risque par le modèle, mais non-perçu comme tel par ce commercial. Il y aura cependant un risque plus important de passer à côté de clients qui partent", argue Didier Gaultier.
"Plus la complexité du réseau de neurones sera grande, moins il sera transparent et ses résultats interprétables"
Quant à l'apprentissage profond ou deep learning, il est particulièrement adapté aux set de données d'entraînement non-structurées (images, vidéo, sons...) et en gros volumes. Très utilisé pour la vision par ordinateur et le natural language processing (NLP), les réseaux de neurones sur lesquels il s'appuie impliquent de facto des structures complexes pour parvenir à reconnaître les images ou les voix. Un réseau de neurones devra multiplier les couches et les nœuds dans l'optique d'encaisser des volumes de variables très vite massifs : une image 4K par exemple affichera autant de pixels que de variables, soit 8,3 millions. "Plus la complexité du réseau sera grande, moins il sera transparent et ses résultats interprétables", commente le data scientist de Business & Decision. Autre contrainte du deep learning : du fait d'un mode d'apprentissage par descente de gradient, le temps et la quantité de ressources informatiques nécessaires à l'entraînement augmentent de manière exponentielle avec la volumétrie du dataset et la complexité du réseau de neurones. "D'où l'importance de bien choisir son architecture de traitement en optant pourquoi pas pour des processeurs spécifiques type TPU", souligne Didier Gaultier.
Deep learning rime avec transfert learning
Reste un apport propre au deep learning qui peut se révéler bien pratique : la possibilité de réaliser du transfert d'apprentissage. Explication : un réseau de neurones pré-entrainé pourra être repris et adapté pour un projet spécifique, en y ajoutant des couches centrées sur les caractéristiques additionnelles voulues. Dans cette logique, un modèle open source de reconnaissance d'images pourra par exemple être personnalisé et "augmenté" en vue de détecter des pièces détachées défectueuses sur une chaîne de montage. De quoi accélérer le développement de l'IA recherchée (lire l'article Le transfer learning : principal levier au service du deep learning).